
Reprinted from Meridian Magazine (25 Jan 2006).
©2006 by John P. Pratt. All rights Reserved.
| 1. Dizzy Bear |
| 2. History of Bible Codes |
| 2.1 Code Breakers |
| 2.2 Criticisms |
| 2.3 State of the Art |
| 2.4 Weaknesses |
| 3. New Approach |
| 4. Torah Tutorial |
| 4.1 CELS encoding |
| 4.2 Two Witnesses |
| 4.3 Spanning Codes |
| 4.4 Reverse Codes |
| 4.5 Linked Codes |
| 4.6 First Occurrence |
| 5. Back to Eden |
| 5.1 Wheat from Chaff |
| 5.2 All in "Garden in Eden" |
| 5.3 A Mandala |
| 5.4 Contextual Crosses |
| 5.5 Overall Probability |
| 5.6 Adam Centered in Eden |
| 6. Conclusion |
| Notes |
Tarnished "Bible codes" may yet shine under new light.
Nearly a decade ago, controversial "Bible codes" were widely publicized, which supposedly proved the existence of God by the discovery of secret coded messages in the Hebrew text of the Torah (the five books of Moses).[1] Then the hype fizzled when critics unveiled similar messages in English in secular texts such as Moby Dick, which were obviously due to random chance.[2] The final nail in the coffin seemed to be a scientific refutation in 1999 to the professional paper which had given it credence in the first place.[3] Now, like the phoenix rising from its own ashes, the Bible code phenomenon may be returning as a renewed wave of interest is growing, based on new discoveries which claim to overcome the objections. After reading one of the latest books attempting to revive the subject, Bible Code Bombshell by Edwin Sherman,[4] I felt that some of his claims were true but that others were not. To me, what is needed is a new approach which can separate the wheat from the chaff.
After a brief historical summary, this article enumerates my specific objections to the way the current research is being conducted, proposes what seems to be a better approach, and then tries it out on a few verses of Genesis. Preliminary results seem encouraging enough to share, even though the new theory is currently only in the prototype stage.
Is it possible to determine with virtual certainty whether or not an author intentionally used the proposed Bible code method to encrypt secret messages into any text? That may be an important question for those who have studied Bible codes because debunking methods have left disillusioned believers with the impression that any message whatever can be found in any sufficiently large text, so it seems to follow that one could never know with confidence whether a given message was indeed really encoded intentionally by the author.
Before discussing the actual Bible codes, let us attempt to answer that question by considering an example in English I wrote to illustrate the proposed encoding method: the allegory of "Dizzy Bear".
"Dizzy Bear" Brent: neater, no, nuttiest
Brent; rambling,
Big and ageless.
Brent wondered what it meant. He knew he might look like a big, rambling bear, and that he had been called "nutty" at times, but never "Dizzy Bear" nor "ageless."
His father liked puzzles, and Brent had received cards from him before with acrostics hidden in the verse. Sure enough, his initials D.B.B. were the first three letters of each line and also of each of the first three words of the first line. That explained at least the first letters of the nickname "Dizzy Bear", but he suspected there must be more. The words "neater, no" stuck out like a sore thumb.
He took it to one friend for help, but the reply was, "I do not believe in poetry puzzles, so it would be pointless for me to look for signs of intelligent design in poetry. That just isn't scientific, because even if I found something, it could never be proven that it was not the product of random chance."
So Brent gave the card to his mathematician friend JoAnn. She agreed to be open-minded enough to look for hidden codes. She started her investigation with the word "neater" which just didn't seem to fit, and soon discovered that starting with the "B" in "Bear" and counting every third letter, it spelled out "Brent." She calculated that there is only about a 1/5,000 chance that a 5-letter word that described the subject would appear encoded by chance with equal letter spacing in such a short text, and such that it formed a perfect cross (See Figure 1).[5] So she felt she had discovered an encoded word which the author must have had in mind.
|
She found another encoding of "Brent" crossing through his name in the text, this time counting every fifth letter, and again beginning on the "B" in "Bear". Her hypothesis had correctly predicted a future discovery, which is the whole point of the scientific method. She estimated that there is only a 1/1,000,000 chance that an average topic word of 5 or more letters would be found crossing itself twice in so short a text.[6]
When she tried extending the second discovery, it spelled out "DBrentBriggs," even including the capital letters. She knew his surname was Briggs, so this put it so far beyond chance that she didn't bother calculating the odds. She now knew that the code was real.
But what about the "D" in "DBrent Briggs"? It is capitalized, just like the other two names, and those letters exactly span the entire text, as if by design. Was "Brent" really his middle name? Suddenly the double acrostic jumped out at her, and there was no doubt in her mind that his initials were indeed D.B.B.
If his surname "Briggs" was encoded, then perhaps his first name was also. She started counting letters from the only capital "D", following the example that "Briggs" was capitalized. Sure enough, in no time she discovered the name "Dan" by counting every seventh letter. What are the chances of another name just appearing like that, starting on the capital letter indicated by the acrostic? She felt it just had to be right.
JoAnn reported back to Brent that she had cracked the code. She proudly announced that she had discovered that his full name was "Dan Brent Briggs." To her dismay, Brent told her she was wrong! She begged for another chance, which of course he granted.
When she reconsidered her reasoning, everything looked perfect up to actually discovering his first name. There was no question that the names Brent and Briggs had been coded according to her hypothesis. And "D" just had to be his first initial because of the acrostic. The mistake must have been to accept "Dan" as the first name found. She realized that it was not improbable to find a 3-letter name there just by chance, even in a short verse. All she would have to do is find the next vowel and then count that same number of letters and land on a likely consonant. Maybe his name was "Don". Wishing that she had done so before embarassing herself, she now calculated that there is nearly a perfect chance of finding at least one 3-letter name starting on that very "D."[7] She had allowed her enthusiasm to cause her to announce results prematurely.
To make it easier to find names, she wrote out the verse in lines spaced by five, being the spacing between the letters of the second encoded "Brent" she found. Mathematics told her that encoded names with any spacing would show up in straight lines in that diagram if the lines were extended at the edges to repeat letters if necessary. She was then shocked to find "Den" (short for Dennis) spaced at both 6 and 11, "Dog" (a nickname?) spaced at 21, and "Dil" (short for Dilbert) spaced at 26.[8] And there could be even other longer names. How could she know which was right? Or maybe those are all there by chance and his first name is Dumpelstilskin, too hard to encode, hence only abbreviated. How could she possibly tell which name, if any, was correct? Maybe there was no new revelation to discover.
She now realized what a huge advantage it had been to already know that his last name was Briggs. She persevered and finally discovered the name "Dennis" by extending out the name "Den" she had found spaced every eleventh letter. She squealed with delight when she found it also ended on the very last letter of the verse, as did "DBrentBriggs" (see Figure 2). She calculated that the chance of finding a common six-letter name, which also followed the established pattern of spanning the verse, was only about 1/18,000.[9] Now there was no doubt that "Dennis" was the name purposely hidden in the codes by its author, and she was right.
Afterward, Brent went to his father, the creator of that one verse (or uni-verse), and thanked him for having taken the time to write it and code it so cleverly. His father was grateful that his son had believed in him enough to study his words carefully. Brent then asked if the inclusion of the second name "Den" was there by chance or by design. His father replied that he didn't plan that name at all, but it was there only by chance, even though it also followed his coding rule of intersecting the name "Brent" in the text.
 |
The probability of finding an example produced by chance of the full name, consisting of at least 12 letters (which could include up to 2 initials) of a person mentioned in a text by their own first, middle or last name (consisting of 5 or more letters), encoded within 100 consecutive letters which include that name, such that both the full name and one of their three names (of 6 or more letters) exactly spanned each other, and also with the contextual name again encoded in a perfect cross, is about one in 14,000,000,000,000,000,000,000.[10]
To grasp the magnitude of that number, it means that if there were a biography of every person who had ever lived on earth since Adam, that mentioned one of their names a thousand times, and an equal number of novels and news stories had been written that did likewise about real or imaginary people, and then all of that literature were searched to find an example meeting those criteria, there would only be a one in a hundred million chance of finding even one success![11] And that is not even requiring that all of the encodings have the first letters of each name capitalized, nor requiring the double acrostic, as in the "Dizzy Bear" example! Thus, if the coding is structured well-enough, then it becomes clear that it didn't occur by chance.
One of the first examples found was the following. Starting with the first Hebrew "t" (taw) in Genesis and counting every 50th letter, it spells out "torah."[14] That by itself could be due to pure chance and hence meaningless, but the same effect is also observed in Exodus. That is, beginning on the first taw in Exodus, and counting every 50th letter, again yields "torah." The probability of that occurring by chance in a randomly selected chapter of the Torah is only about 1 in 1800, so the possibility that such codes are real seemed to merit further investigation.[15]
This type of code, in which one finds a sequence of letters by skipping the same number of letters in succession, is called an "equidistant letter sequence" (ELS). The number of letters counted to the next letter is called the ELS spacing. The "Dizzy Bear" example used ELS codes of spacing 3 ("Brent"), 5 ("DBrentBriggs") and 11 ("Dennis").
Little progress was made from this point before computers could be used to easily do the counting for us. Excellent, inexpensive programs are now available to do this laborious job.[16] And when they were used, then it became almost too simple to unleash their power to find codes everywhere. For example, "torah" is found encoded 34 times at various ELS spacings in the first chapter of Genesis, which is about the number expected to be found just from random chance.[17] So how can we know if any of those codes were intentionally put their by the author?
When that method seemed to produce meaningful results, a paper was published by a peer-reviewed statistics journal in 1994.[18] With that credibility, a best selling book was written that brought the result to the public awareness, written by an investigative reporter who sensationalized it.[19] Without appreciating the underlying statistics well enough, but knowing what people buy, he immediately applied the techniques to predict the future. His book did much to discredit the entire field, for it was easily refuted. But there were also serious criticisms of the original scientific paper itself.
But even a few errors in the text will cause errors in the codes over any interval containing an error that either adds or deletes a letter. Another response to this criticism is that we are talking about God as the author, and he could know ahead what letters would be left out, and could have planned for that contingency. Thus, some researchers look at codes separated by thousands and even hundreds of thousands letters, and take them very seriously.
More serious criticisms of the work deal with what is sometimes called by statisticians "snooping" and "tuning." Snooping occurs when one peeks ahead at the data, and then proceeds to calculate the probability of that data being found using assumptions based on not having looked ahead. Tuning refers to changing ones definition of what constitutes a success to fit the data which has been snooped. Most often, these two cardinal sins in statistics are committed inadvertently rather than maliciously.
The demise of the scientific paper on which so much was based came mostly from tuning criticisms. It was pointed out that many of the rabbis whose names were found associated with their birthdates were called by appellations that worked. This is a classic example of tuning. When all names of the rabbis were included to allow for failures, the effect was found to disappear.
For me, the problem is that when I read the early chapters of the book dealing with the above, I was grateful that finally that work was progressing, and that I could rest easy that someone else was doing it just fine. But then as I read the rest of the book, I felt that the researchers have again had wandered off into Fantasy Land. So, rather than review the new work, I feel the need to vent my own criticisms of all of the work which has been done to date, and to offer a proposed solution.
Threw out Baby with Bath? Most of the sequences used to discover the codes are now considered invalid because they do no meet artificially imposed statistical standards. Some insist that words must be found in pairs, some want to disallow all codes less than five letters long. Those are both indications of our ignorance, rather than derived coding standards used by the encoder. Then I look at what is allowed, certified as rare codes, and see very questionable results.
Separating Wheat from Chaff. All that has been done so far is based on statistics. When a word is found more times than expected, there has been no good way to tell which are the "extra" codes, most likely to have be included by design, and which are the random finds. What good is a Bible code if we don't even know which codes are real? How can we possibly take the next step of reading them?
New Revelation? Many artificial restrictions have been placed on the possible message content of the codes, such as that they cannot predict the future, and that no new religious truths might be contained in them. Since when is God restricted on what he might want to reveal? What is the point of a hidden message if it is vacuous? This restriction was apparently proposed only to avoid offending someone with different beliefs.
Surface Text Important. The surface text (that is, the raw text, ignoring codes) is often ignored when searching for Bible codes, especially where large ELS spacings are involved. The best examples in all five of the new types of discoveries summarized above were in the context of the same topic in the surface text. But there is no formal requirement to have the surface text refer to anything related to the codes.
Minimum Spacing. One type of wheat/chaff filter has been proposed. It was decided to pick ELS codes with minimum or near minimum letter spacing as the rule to determine their importance. That seems totally arbitrary to me. Each of these rules need to be proven as useful before being written in stone.
Outrageous spacings. Bible Code Bombshell lists an ELS code for "Saddam Hussein" in a sequence with a skip of 150,684.[22] That is so long that it spans nearly the entire Hebrew Old Testament, with each letter being taken from a different book. Now, God moves in mysterious ways, but that is really pushing my credulity. Even though I believe that God could know ahead exactly what books would be written with what words and then arranged in what order, I still would have to see some very convincing evidence to believe that such a code is real. The most convincing codes I've seen span very short distances (less than a chapter), over which I could believe that no copyist errors have been made since the original revelation to Moses. The longer the sequence, the more probable the chance for error.
Close Doesn't Count. My work in calendar dates has shown me that God's work is amazingly accurate. While other chronologies attempt to establish religious dates to within a year or a decade, my work has asserted that all of the important dates are usually known to quarter-day accuracy. Bringing that bias with me when I examine the evidence for Bible codes, I am unimpressed with the metric proposed by the researchers to have two codes "close" to each other. The only codes I'm impressed with so far are direct hits. That is, the encoded word shares a letter with either the surface text or another encoded word. I might be proven wrong on this point, even in my own calendar work, but I would need to see some very convincing examples. The problem with "close" is that it allows far too many hits and leads to confusion and spurious codes to be accepted as real. We need many ways to separate the wheat from the chaff.
Order. One of the best indications of intelligent design is order. When I was encoding the "Dizzy Bear" example, I put as much order into the example as I could, to make it absolutely clear without any need to calculate complicated probabilities, that the encoded words truly were intended by the author. God's house is a house of order, not a house of confusion (2 Chr. 29:35). That is because order is a clear indication of intelligence. Most of the Bible code examples published show only a superficial order imposed by the researcher but not clearly intended by the author.
Thus, let's consider a new approach which addresses these weaknesses in the current theory.
What I propose is that a subset of ELS codes be considered. The requirement is so new and different from what has been done, perhaps they should have a different name. Let us call them Contextual Equidistant Letter Sequences (CELS). That is, the code must relate to the context in which it appears, or else it is rejected as random. When the spacing is so large that a variety of subjects are discussed in the surface text, then at least one of the words intersected must clearly relate to the encoded word.
This contextual requirement is a little slippery, and opens the door to "tuning" criticisms. What one person thinks relates, another does not. But sometimes it is crystal clear. In the "Dizzy Bear" example, the encoded words "Brent", "Briggs", and "Dennis" all intersected the word "Brent" in the text. Note that such is only possible if the encoded word contains the very same letters as the contextual word ("Dennis" contains both an "e" and an "n" as does "Brent"). This is a very stringent requirement. It is an extreme case of what the original statistical paper was using as a metric. Those researchers required that the two sought terms intersect "near" each other. My proposal is that they intersect in exactly the same letter, and moreover, that at least some letters be contained in a related surface words. While that method may seem harsh because it eliminates so many codes, it also allows other codes to be accepted because no longer is there a requirement for two words, nor long words. A single short encoded word might be meaningful if it is composed of letters found in meaningfully related words. A preliminary attempt at an objective way to determine which words are related is proposed below, but first let us consider what might be a "Bible Code Tutorial".
As mentioned above, some of the first ELS codes found were of the word "torah" right at the beginning of the Bible. If that is meaningful, why would the word "torah" be used? Because the codes only occur in the Torah? I don't think so. Let's consider another idea. Suppose "torah," which means "law," was chosen to show examples of the law which governs the Bible codes. If so, some encoded "torah" words may have been designed as a tutorial to show exactly which are true codes and which are spurious. Let's try that hypothesis.
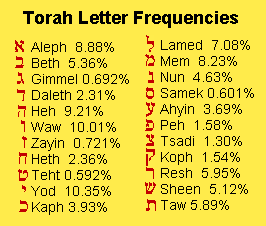 |
Now that we have examined this code more carefully, three new experiments suggest themselves to extend the theory:
The number 50 is a special number in the law of Moses because the holy day Pentecost is counted as the fiftieth day, and the jubilee as the fiftieth year. Perhaps all authentic Bible codes must have an ELS spacing of 50.
The four words might be an explanatory addition to the text. Let's consider the possibility of what might be called "explanatory codes." In the "Dizzy Bear" example, the codes gave Brent's full name, in case someone wanted to know it. Such codes would be like footnotes or hyperlinks to more information for those interested.
The four words nearly span the description of what occurred on the first day. Perhaps some codes are "spanning" codes, possibly indicating that the encoded word relates to everything spanned by it. In the "Dizzy Bear" example, the two principal codes exactly spanned the entire text, which was an indication that they were intended and not random.
Thus we have a second witness that the codes are real, and support two of the hypotheses proposed from Lesson 1. That is, the code was found with spacing of 50, it was found in meaningful surface text words, but it doesn't clearly span any concept.
Now let's do a spanning experiment, to see if that concept leads anywhere.
So in preparing for this article it occurred to me that the Lord might have used the same idea. The first experiment I thought of was so successful that I feel only to include that one example. Chapter 1 of Genesis spans the activities of the entire six periods of creation. What if one "torah" code spanned that entire chapter? I looked at the last word of the chapter and it begins with heh, the same letter that "torah" ends with. The taw in the first "torah" is the last letter of the first word of the chapter. That in itself shows an ordering which is common with the Lord, that the last is first and the first is last. Moreover, the first letter is found in the word "In the beginning" and the last in the word "sixth" which exactly describes what section is being spanned.
Thus, the experiment was to see if the middle two letters of "torah" are found in exactly the right positions in the text to form a spanning code with these two letters. The chance of that occurring in a randomly selected text from the Torah is only about 1/500.[23]. Most statistics studies only require a probability of 1/20 to be considered meaningful, so this seemed like a good test. Of course, if it failed, it might only mean that the Lord did not choose to encode that word in that manner.
The experiment was a success. The word "torah" is indeed found in an ELS sequence of spacing 554, the only possible spacing to join the two letters indicated. Looking at the two words containing the other two letters, they are "its" (Gen 1: 12:12) and "morning" (Gen. 1:23:4), which do not seem meaningful. If this code is real, as appears to me, then the results of this experiment indicate 1) that the ELS spacing does not always have to be 50, 2) an ELS might span an entire chapter, and 3) not all of the surface text words of a spanning ELS need be meaningful. The purpose of the code might be only to show that the encoded word applies to a particular text as a whole, rather than only a single word therein.
In Numbers, "torah" is again found encoded beginning in the first verse, but this time the word is in the reverse order, starting with the heh and spelling "torah" backwards. Reverse codes are well known in Bible code research, and are indicated by a negative skip distance, -50 in this case. It can be thought of as finding the last letter first and spelling the word backwards, or if the first letter is found first, then one counts backwards to get the next. Because the implied tutorial led us directly to examine this verse, to me it means that reverse codes are as real as the forward codes. Of course, both need a lot more evidence to have a truly compelling proof of their existence. In this case the surface text words also seem meaningful (Num. 1:1:4 "Moses," 1:1:16 "Egypt," 1:2:12 "names," and 1:3:10 "them") because the first chapters are about Moses recording their names and numbers.
A side discovery here, which was not part of the experiment, might be useful in designing future experiments. There is only a 1/16 probability of finding even one "torah" at spacing 50 in Numbers 1, but two were found. The other is a forward code ending in the very last verse. Again that indicates much more order than merely having been found at some random place in the chapter, as would be expected by chance. And again we see the first and last, with reversals. That code looks real to me.
Checking Deuteronomy 1 we find "torah" once in chapter one, ending in the next to last verse. It has meaningful surface text words (Deut. 1:42:14 "You be struck" 1:43:9 "and acted proudly," 1:44:9 "as," 1:45:4 "Jehovah"). That is very similar to the finding in Numbers of a code near the very end of the chapter, rather than at the very beginning. It cannot be counted as a success for this experiment, but it might be a clue to how the codes are used at the beginning and the end.
Thus, technically, the experiment failed for all three of the books of Leviticus, Numbers, and Deuteronomy, because I was looking only for forward ELS codes at the beginning of the first chapter. Had I been looking for reverse also, then Numbers would have been a success, but the odds would have been twice as likely to have been there by chance. In science we often learn more from the failures than the successes.
There is a principle in Hebrew writing called "chiasmus," which is that when one finds repetition at the first and last, then look to the middle for what is the most important. We have found forward codes at the beginning of Genesis and Exodus, and also at the end of the first chapters of Numbers and Deuteronomy. If the Lord is following a chiasmus pattern, then the most important code should occur in the first chapter of Leviticus, the middle of the five chapters.
Looking there we find something very interesting, which has hitherto been overlooked as far as I know. Starting in the second verse, there is a reverse code for "torah" with spacing -60, and then beginning on its final "taw," there is a forward "torah" at spacing 40. The fact that 40 and 60 average to 50, which was what we were looking for, might be intentional. As a working hypothesis, let's suppose that the tutorial is real, and that the lesson here is that encoded words with different ELS spacings can be linked by sharing a letter.
There are two very intriguing aspects of linked codes. First, they increase the amount of order and are less probable than separate codes. To convince yourself of that, imagine that two examples of a very rare code have been found in a very long text. For example, suppose "Adam, the first man" were found at two different ELS spacings in Genesis, when one would not expect a phrase that long to occur even once. Now, out of all the places they might have occurred, suppose that they both share the same "A" as the encoded letter for "Adam." Without doing a lot of calculations, it is hopefully obvious that such would be much less likely than having two separate sequences.
The second nice feature of linked codes is that it consumes fewer letters for encoding. Why use up eight letters for two encodings of "torah" when seven will do. In fact, we have already seen this. The same taw was used in the original "torah" found with spacing 50, and in the spanning code of spacing 554.
As I thought about how far this principle of "economy of letters" could be pushed, I wondered what is the most codes per letter that is possible? This may be an important question for short words. Most Hebrew word roots contain only three letters. And yet three-letter ELS codes can happen so frequently that many Bible Code researchers reject all of them because they have no way to tell which are real or not. The name "Dan" really did appear in the "Dizzy Bear" verse, complete with the capital "D," without me having planned it. But now suppose that my friend's name had indeed been Dan? How could I have encoded the verse to make it clear that "Dan" was not there by chance?
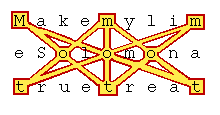 |
"Make my lime, Solomon, a true treat."When written as three lines of nine letters each, the name "Tom" is found encoded seven times using only nine letters (See Figure 3). I do not see how anyone would need to calculate any probabilities after seeing the pattern to convince themselves that these seven occurrences of "Tom" in only 27 letters of text could not have been due to chance. I could have included one more "Tom" in by using "demo" instead of "lime," but chose not to because that would have decreased the ratio of codes to letters and also would have marred the pattern. After I created this illustration I recognized the pattern as one form of the "mandala" which is believed to have been used in Egyptian figures. Hence, I'll refer to this pattern as the mandala.
Thus, this important lesson from Leviticus may be a key to recognize encodings of three-letter Hebrew words.
This seemed like a good example on which to test my new theory, that if those excess codes were truly put there on purpose by the author, then 1) they should be CELS codes which explain more about either specific key words they intersect, or sections of text they span, as in the "Dizzy Bear" example, or 2) they could show patterns of maximizing the number of encodings while minimizing the number of letters, as in the mandala pattern of "Lime Treat". My current theory discards all codes which do not meet either of those criteria. Moreover, because this passage contains the first reference to Eden, it seemed qualified to test the hypothesis that the first time a major concept is introduced, there might be special codes around it to explain it better.
I checked out every occurrence of "Eden" as an ELS of any length greater than one and looked up what word each letter occurred in, using an interlinear Hebrew English Bible. After sufficient data snooping (which can be compensated for when calculating probabilities), I decided to focus on Gen. 2:5-10, containing 329 Hebrew letters. In a passage of that length chosen randomly from the Torah, one would expect to find the three-letter Hebrew word "Eden" about 5 times just by chance. Note how prolific these codes are. If one did not calculate probabilities, it might appear amazing to find any word encoded five times in such a short passage. But in this case, "Eden" appears in ELS codes 15 times. The probability is less than one in 8,300 for that to occur by chance in a random passage,[29] so this looks like a fine place to see if context can help us determine which codes might be real and which are not.
By checking the surface text words, nine ELS codes were found that intersected key words in the surface text in a meaningful way, while six did not.[31] By the new theory, those nine would qualify as CELS codes, and the other six are discarded as having been caused by chance. Thus, to me this was encouraging, because it so closely matched what probability predicts, namely, that there would be about five ELS codes found by chance alone. But this result is not compelling because there is a better than an even chance that any one ELS will intersect some key word.[32] This is tricky business; nevertheless, it is hopefully a step toward separating out real codes, if there are any, from wishful thinking. It turns out all nine of those CELS hits are impressive for other reasons, as we shall now see.
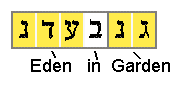 |
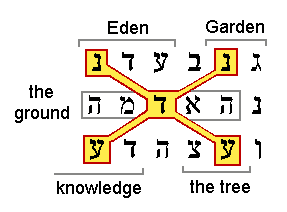
Now we shall see that those CELS codes not only all intersect the two most important words, they also form meaningful patterns. Those nine words fall into three groups. One of the nine intersected only key words. That one had an ELS spacing of 83, and comprised the letters Gen 2:5:8:1 in "herb," 2:6:9:3 "ground," and 2:8:5:4 "Eden." Four of the nine formed a nearly complete mandala figure as in the "Lime Treat" example, and the other four formed two crosses in meaningful contextual ways. Let us now consider the strength of those patterns in more detail.
Figure 4 shows the words "Garden in Eden" as they appear in Gen. 2:8. Remember that Hebrew reads from right to left. The word "Garden" has two letters, "in" has one, and "Eden" has three. This figure was included to help you recognize the word "Eden" to better appreciate these results.
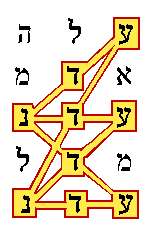 |
Do any of the three letters which complete this figure occur in key words? The answer is that only one does, but probably two should have. The word on the top row is in "went up" where it states that "there went up a mist from the earth" (Gen. 2:6:2:2). To me that is not a key word. The word in the next row is "the ground" in Gen. 2:7:8:3, which was chosen as a key word. The word in the row between the two "Edens" is "pleasant" (Gen. 2:9:8:4) which perhaps should have been included in my list of key words. It is practically a synonym for the whole idea of the Garden of Eden. This is where the temptation arises to "tune" the definition of a "success" by going back and changing the list of key words. But "Eden" also sounds like a good place to avoid temptation, so I will resist the urge.
The chances of this much of the mandala pattern occurring around the two words "Eden" in a text from the Torah, and including at least one contextual keyword are less than 1/39,000.[34] Note that this pattern approach is starting afresh to calculate probabilities. There is only a 1/39,000 chance of finding such a nearly complete mandala, without even considering the other 11 "Eden" encodings found in these six verses.
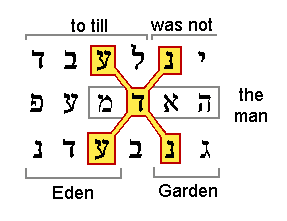 |
When the spacing between rows is changed to 59 letters, we see in Figure 6 of the type of cross meant. The two words "Garden" and "Eden" appear to be connected to the words "was not" and "to till" in the phrase "there was not a man to till the ground" (Gen. 2:5). What makes it meaningful is that the letter at the center of the cross appears in the word "the man." Even though none of those three words was on my key word list, it still forms a phrase: all the contextual words put together say "was not a man to till the Garden in Eden" which is nearly the same as the phrase "there was not a man to till the ground." This is much like what we saw in the very first "torah" example, where the contextual words formed another sentence much like the surface sentence.
The chance of finding such a connecting cross using the word "Eden" to connect the words "Garden" and "Eden" to any two others is 1/88.[35] For now, we will not include any factor for the five words all forming a sentence because the other three words were not on my key word list. Perhaps future studies can take this sentence-forming feature into account.
 |
Now we can finally compensate for the "snooping" done earlier. We started out with a set of six verses which for which we knew there was only a 1/8,300 chance of containing so many encodings of Eden, if there by chance. What is the chance of finding something with a 1/28,000,000 probability given that we started knowing it had purposely been selected because of having only a 1/8,300 of existing at all? The answer is that one divides the two probabilities, to get about 1/3,000.[37] So starting from where we did, there was only a one in three thousand chance of getting these results. That is far less than the usual 1/20 confidence level required for most statistical studies.
 |
The ELS codes allowed by this new theory are called "contextual" ELS codes (CELS) because only codes related to the surface text can be considered as having any chance of being real. This work is only in the prototype stage, and no scientific metrics have yet been devised. Indeed, an objective approach appears elusive because the whole definition of what is "related" seems subjective. Nevertheless, as a first application, with an eye toward developing a rigorous scientific method later, a study was made of only one occurrence of two words in the Hebrew Genesis: "Garden" and "Eden". The precise words in which all of the letters of the fifteen ELS sequences for "Eden" in Gen. 2:5-10 were examined, and nine were found to qualify as CELS codes, all of which intersected those two words. Then patterns they formed were examined which decreased the number of letters required for so many codes. That is precisely a technique that would be expected to be found in work truly encoded by the author as it would form less probable combinations, as well as leave more locations available to include other encoded words. A preliminary estimate of the significance level of this discovery is 1/3,000, far beyond the usual 1/20 required.
It must be emphasized that the results being reported here are entirely preliminary. Only one occurrence of two key words was studied using the new technique, and even then only intersections of the topic word with those two were considered. Statistics call for large samplings, and so there is much work left to be done. The only reason that it appeared worth publishing with such a small sample was that it proved so rich as to require several illustrations to show the many dimensions of just those two words. The other reason is that I plan to go back to calendar work, and hope that others will continue and perfect this new approach, if it continues to appear fruitful.
The conclusion at this early point in new research is that it appears that at least some CELS codes are real, and the contextual analysis may prove to be the key to separating true from false ELS findings. Indeed, it now appears that time might show that the Bible code phenomenon could unfold much as did the miracles of Moses to Pharaoh: the skeptical magicians were able to duplicate the first few, but then God's miracles kept multiplying until they were compelling. To me, the hand of God is being manifest in just two words of his great revelation to Moses. It is no wonder that we are commanded to live by every word which proceeds from the mouth of God (Deut. 8:3).